Trunk Based Development is all the rage at the moment. Heavily advocated by experts. However, we found that Trunk Based Development has some serious flaws that for us were easily fixable as long as we broke some of the rules that the experts claim absolutely must be followed. Ganted in 2013, when we started our journey, we were not doing Trunk Based Development correctly, but our starting point was where a small software company had got to by listening to the Trunk Based Development experts.

What is Trunk Based Development?
Trunk Based Development and CI dictates aspects of how you use version control and your CI-server. It has numerous variants, but the rules that seem to be generally agreed upon are:
- All developers push code to to trunk (the master branch in git) on your shared central repository (origin, often GitHub), at least once a day - more often is encouraged.
- Any code pushed to trunk automatically kicks off the CI-server and tests are run on the code.
- If tests fail and the build is red, it is the responsibility of the person who pushed the code or the entire team to fix the build and turn it green quickly. A period of 10 minutes has been mentioned as a generous upper limit of how long it should take to turn the build green.
An artefact of Trunk Based Development is that trunk is in what people working with Trunk Based Development call a “releasable state”. All the tests pass on trunk, so potentially you could release it to production.
What problems does Trunk Based Development solve?
The main problem that Trunk Based Development directly solves is the elimination of Big Scary Merges. There are plenty of stories of people working in feature branches for months and months and the horrors that occur when it’s time to integrate the feature branches into trunk. An additional problem that has been claimed solved by Trunk Based Development is that it allows you to do refactoring. This is a variant of the Big Scary Merges, as refactoring code in long-lived feature branches will potentially result in a merging nightmare.
How was Trunk Based Development broken for us?

We used the Trunk Based Development inspired process for a number of years before discovering a better solution. What follows are some of the problems we experienced with our process:
- When the build on trunk turns red, everyone else is blocked from deploying
- When the build on trunk turns red, it’s necessary to notify everyone that they should not push code to trunk because fixing a red build is hard enough without having new code coming in on top of the broken code. Plus, the new code could potentially break other tests and you can end up fighting for a long time to get the build green again.
- Sometimes the devs who broke the build overlook that the build turned red, or even went home for the day. You have the whole team in a kind of CI-alert mode, where you help each other keeping an eye on the trunk build. We saw what I’ve named the “CI-police”: developers who were just watching CI more closely and were pushing for others to fix a red build. I was part of this CI-police, and all of us in the CI-police agreed that the role sucked.
- The CI-police are also responsible for reminding developers to run tests before they push code to trunk. We tried with git hooks, but they are very inflexible and run all the tests again even if you’ve just run them, slowing you down.
- Blinking tests; let’s be honest, we’ve all had them. Blinking tests are horrible and should be fixed fast. With Trunk Based Development, the awfulness of blinking tests is multiplied, because the blinking test triggers the CI-alert mentioned above. But a blinking test can be hard to fix. You can’t just revert the last commit because it may have started blinking 10 commits ago, (it just ran green the first 9 times and now it’s red on some completely unrelated commit). A blinking test with Trunk Based Development can be very disruptive for everyone on the team.
- Feature toggles. To be able to release trunk more often under Trunk Based Development, you have to add a lot of feature toggles. Feature toggles cost time and effort to add and they also increase the complexity. Plus you have to go and remove them later.
- Refactoring. With Trunk Based Development easy and small refactoring is quite easy. But doing a big refactor, where you have to push code to trunk every day, requiring green tests all along and keeping trunk in a releasable state can be quite hard to do. Branch by abstraction is also not always easy to do. A much easier way to work is to keep your work isolated in a branch longer, with broken tests that you can then fix.
How we fixed our process

To fix all the problems described above, we applied some principles:
- You cannot block or interrupt another developer working on something unrelated to your work. The only valid reason to interrupt another developer is to coordinate business requirements. The interruption in never initiated in any way by the automation tools around the development process.
- A developer can deploy her or his code to production when it’s ready, without asking permission or coordinating with anyone.
- Remove or automate any place in the process where a human needs to be following up on or pushing another human to do some work. This principle goes beyond what’s described in this blog post to also include some Product Owner work, bug fixing, monitoring of the error log, etc.
- In order for trunk to be in a releasable state in the truest sense of the words, we automatically deploy every code push to trunk to production.
Based on these principles, we came up with what we are calling Koritsu. We chose that name because Kōritsu is the Japanese word for efficiency, and for us Koritsu has been the most efficient development process any of us have ever tried. Plus we heard giving things Japanese names is making a big comeback. At least we think it’s better than this method of naming things
What is Koritsu?
I explain Koritsu in this video from the GOTO conference in 2015. We’ve been doing Koritsu for a while now with success:
These are the central components of Koritsu as we practise it:
- Everyone works in branches.
- You can work alone or several developers can work on a branch, anything that takes more than two days should be worked on by at least two developers.
- Branches should be merged to trunk often - at least once a week. A branch for a quick bugfix can live for only a few minutes.
- If the work takes more than one week, do a feature toggle or hide the functionality in the GUI, merge your branch to trunk and continue work in a new branch off of trunk. Merging your branch to trunk is done by the CI-server only. No developer pushes code to trunk directly.
- You signal that you want a branch merged to trunk and deployed by pushing a copy of the branch to a new branch name that starts with “ready/” onto origin. We call this a “ready-branch”. The ready-branch is a low overhead copy of the branch, just a git pointer to a commit.
- The CI-server is triggered as soon as any ready-branch is created on origin. The CI server checks out trunk, squash merges the ready-branch into trunk, runs all tests, pushes the merged code to origin and deploys the code to production. A merge of a branch to trunk is always also a deploy to production. We call this a “ready-build”. If the merge of the ready-branch into trunk has merge conflicts, the developer is notified and the build exits. If one or more tests fail, the developer is notified and the build exits. The last thing the ready-build does before exiting is to always delete the ready-branch from origin. You can see the bash script we use for this step on GitHub. The script is a bit messy, but you should be able to easily clean it up for your own use.
- For each project, ready-builds do not run concurrently. In other words, a maximum of one ready-build can be in progress at a time for each project. Simultaneous requests for ready-builds by several branches at the same time are queued and executed sequentially in the same order as they were initiated. In effect, an automated queue of ready-builds.
The branching looks like this:
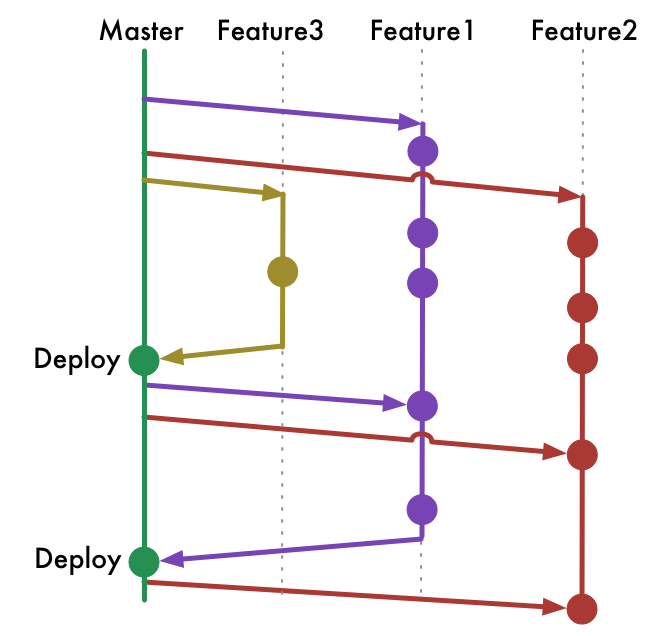
All kinds of merges or branching we do is included in this picture. We do not branch off of feature branches, we do not merge feature branches into each other and we never need to rebase.
Koritsu can seem a bit daunting and complex. It's actually very simple for the developer. You just do your work in a branch and deploy it when you are ready, with a single command line command. That's it, nothing else to do. The rest is automation details, that you don't need to worry about in your normal daily work.
What problems does Koritsu solve?
Koritsu is not optimized to avoid Big Scary Merges like Trunk Based Development. Instead, it’s optimized to never interrupt or block other developers. We have had ten to thirteen developers working with Koritsu for several years, and although situations wherein interruption of other developers do happen, they are very rare. Most of the time, everyone is working in complete parallel without worrying about or even coordinating with developers working on other tasks. We still participate in valuable knowledge sharing, for example: in our daily standup.
So what about Big Scary Merges, when you allow feature branches to live for a week? It’s not been a big issue even a single time in the years we’ve worked with Koritsu. We have had two or three instances where there was some work involved in a merge, but we’re talking about an hours work at most. So in short: Big Scary Merges are a non-issue for us. To be honest, I do not understand the very vocal proclamation many experts are making that you always have to push code to trunk at least once a day. I understand that it’s a reaction to some disastrous experiences with Big Scary Merges, and can be needed. But to me it seems like sometimes it can be an irrational overreaction that can introduce a lot of unnecessary extra work and complexity in the daily work of development.
If we reiterate the problems described with our previous process and approach them with Koritsu the following picture emerges:
- Build on trunk never turns red, because CI-server is a gatekeeper to getting code into trunk, and never allows any code with failing tests to pass.
- You do not need notify anyone on red trunk build since it never happens.
- There is no “CI-police” and no overlooking a red build of trunk.
- You don’t need to run test locally before pushing to a ready-build. A failing ready-build is no big deal. In fact for small changes it’s often more effective to not run the tests locally, have the ready-build run the tests, and get on with your other tasks. Another way to work is just to run the tests you think are affected by your change locally, and let the ready-build run the full test suite. Not running test locally and pushing code felt very wrong after years of Trunk Based Development, but we quickly got used to it and realized it was a good boost to productivity.
- Blinking tests are still not nice. But will potentially be spotted faster and will not cause reverting of the wrong things. In our experience, blinking tests are less painful with Koritsu than with Trunk Based Development.
- Feature toggles: with Koritsu you can add far fewer feature toggles because anything you can develop in a week or less does not need a feature toggle.
- Refactoring: undertaking a big refactor is much easier with Koritsu. You can keep your work isolated in a branch longer, with broken tests that are then fixed.
We’ve been working with Koritsu since early 2014, deploying to production 10 times or more every day. Moving to Koritsu from our previous processs, along with some other process improvements increased our measured productivity by 40%. More than that employee satisfaction increased. We’ve made no major changes to the process for years. There simply is no pain to fix. For us, Koritsu runs super smooth with no issues that need to be addressed. Your mileage may vary, Koritsu is not for big projects with a lot of developers, but it could possibly work for you too.
Relaxing the deploy requirement
We use Koritsu on our mobile development as well. Here, we do not deploy to the Google or Apple app stores on every merge to trunk. Instead, the ready-build deploys to TestFlight and our staging environment on every merge to trunk. Deploying to app stores relies on a manually triggered build on the CI-server. Koritsu still works exceptionally well in this scenario.
Koritsu on our website
The latest thing we have done with Koritsu is move our entire CMS to a homegrown solution, where all assets are in git. All content editors work in markdown and pug and push their new content with ready builds. About 13 people who are not developers contribute content regularly. Each change is run through literally millions of content and SEO-tests before they are allowed into trunk and automatically deployed. Again Koritsu still works exceptionally well in this scenario.
References
Check out the article An Automated Git Branching Flow if you have maintenance branches. Our ready-branches approach was inspired by this.
Koritsu is quite similar to short lived feature branches, except we let the feature branches live for up to a week and automatically deploy every merge to trunk..

